_CMYK_OL.png)
Note: This blog post was originally written in Japanese for our Japanese website. We used our machine translation platforms to translate it and post-edit the content in English. The original Japanese post can be found here.
Kawamura International offers several translation services, including localization. In this post, we’ll focus on localizing large documents. Besides the usual Microsoft Word and InDesign files, we work with various file formats. One format we've been seeing more of lately is DITA — a format often used for manuals. So, let’s dive into the basics of DITA: what it is, and what its pros and cons are. Even if you're not planning to localize your documents, DITA can be a big help in digital transformation, so it's worth sticking around.
What is DITA?
DITA (Darwin Information Typing Architecture) is an international open standard that is XML-based and used for authoring and publishing documents. Because DITA allows documents to be created in a structured way with easy content reuse, it's often used for documents that are information-rich or where the same content is reused in different places.
Unlike a Microsoft Word document, where all content is contained in a single file, DITA consists of a combination of XML-formatted files: "topic" (.dita), "map" (.ditamap), and sometimes "DITAVAL" (.ditaval). Topic files break down (or modularize) a document by topic, and map files define the order of these topics. DITAVAL files handle the conditions within the document and assist with output. You could say DITA is a bit like InDesign books (.indb).
Why use DITA?
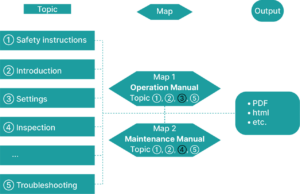
As we just learned, DITA divides a document into topic files. You only need one map for a document — but if you create several maps by selecting and discarding certain topic files, you can easily create documents for different purposes. This means that by using the same topic files in different maps, common content can be reused and updated effortlessly.
For example, let’s say you're creating an operation manual and a maintenance manual for one of your products. In this case, you can create two separate maps — one for the operation manual and one for the maintenance manual. You can then reuse the "Safety instructions" and "Introduction" topic files in both maps, while including the "Settings" topic file only in the operation manual and adding the "Inspection" topic file for maintenance personnel only in the maintenance manual.
Alternatively, you can create maps for different machine models, making it easy to reuse content that’s common across all models.
In addition to reusing entire files, you can also reuse parts of files (called fragment units) by using "conref" and "conkeyref" tag attributes. These tags allow you to keep commonly used phrases and names in a separate file from the topic files. When you use a conref or conkeyref tag in a topic file, the text defined in the separate reference file will appear in the final output document. This means you can easily change a phrase that appears in multiple topics without having to edit each topic file directly. This is especially handy for things like manual titles, UI elements, and function names.

DITA also offers a filtering feature. Filtering helps you control whether certain content is included in the output. For instance, in a car manual, different models of the same car might have different features. You could tag each model name and then specify the model name to be included in the output using a .ditaval file. This would allow you to output only the content relevant to the specific model.
Here’s an example of what a topic file might look like:
| <shortdesc>Features:</shortdesc> <!-- Common content --> <p product="Model A">LED headlights, passenger seat heater</p> <!-- Model A content --> <p product="Model B">LED headlights, heated passenger seats, leather-wrapped steering wheel, premium audio <!-- Model B content --> |
Note: The "product" attribute of the <p> tag specifies the model name.
If you specify in a .ditaval file that only content with the product attribute "Model A" should be included in the output, you'll get the common content along with Model A’s specific content, while excluding Model B’s content.
Updating common content is also easier with DITA. If you create manuals for each model in separate files, like in Word, you’d usually have to open each file and update the relevant sections, which can lead to errors. But with DITA, you only need to update the one file with the common content, simplifying updates and reducing the risk of mistakes.
DITA’s filtering feature is particularly useful for translation. If you only need to translate common content and Model A-specific content, you can easily manage this by adjusting CAT tool filters. These filters can be set to exclude Model B’s content from the translation process entirely or to display it but exclude it from translation.
If you're considering translating a document into multiple languages, you could change the "product" attribute to "destination" and the attribute value to "Spain" or "Germany". This would link the text to a specific language, making it easier to translate and output for each destination.
Disadvantages of DITA
While DITA offers many advantages, there are also some disadvantages. First, to use DITA effectively, you need to have a deep understanding of it. Also, since each file covers only one topic, migrating existing documents to DITA might require significant restructuring, making implementation challenging.
As mentioned earlier, DITA is best suited for documents with large amounts of information and content that is reused across multiple sections. This means DITA’s advantages might not be fully utilized with smaller documents where content is only written once.
Additionally, while you can use style sheets and icons, there are layout limitations, so DITA might not be ideal for documents where visual design is important.
In terms of translation, having more tags can mean more time spent setting up initial filters in your CAT tool — though this can save you time in the long run. Moreover, content might not be translated properly if the functions of the conref tag or other DITA features aren’t well understood. Therefore, it’s crucial that both the translation requester and the translators have a good grasp of DITA to ensure efficient, high-quality translations.
Summary
We hope that the technical talk of this post didn’t scare you enough for you to not notice how useful DITA can be. Up until recently, we were mainly asked to translate documents and manuals created in Microsoft Word, Excel, and InDesign, but the requests for DITA translation are increasing each year.
If you are considering digitizing paper documents, or maybe even turning them into web pages, DITA is extremely suitable for such digital transformation. While implementing DITA can be challenging, the long-term benefits — such as saving time and reducing costs — far outweigh the initial difficulties. As more companies recognize its advantages, we expect DITA to become increasingly popular in the future.
Kawamura's translation services
Kawamura International is certified with ISO 17100, the international standard for translation, and provides translation services based on this standard.
Areas covered include IT and localization, medical devices and pharmaceuticals, tourism, manufacturing, patents, IR and finance, legal affairs, and SAP-related documents. We will assign the most suitable translator to your business and field of expertise. Our translators are experienced, professional translators who have passed our screening standards, so you can rest assured about the quality. Please feel free to contact us with any translation or quote requests.

