_CMYK_OL.png)
Note: This blog post was originally written in Japanese for our Japanese website. We used our machine translation platform Translation Designer to translate it and post-edit the content in English. The original Japanese post can be found here.
Four metrics for evaluating AI translation
In a human translation project, the project usually moves from translation to review to final confirmation. Tools and editors suited to each purpose are used, but, in essence, all of the steps are performed manually (visually).
On the other hand, AI translation projects generally move from AI translation (machine translation, or MT) to post-editing (PE) to final confirmation. The detailed steps or processes differ from project to project, but one of the major advantages of AI translation is the ability to reduce costs and work-hours compared to human translation.
Of course, it is also necessary to maintain quality. Normally, post-editing and final confirmation are still done manually, so using AI translation to output translations with the highest accuracy possible is the key to maintaining and improving quality (as well as to reducing costs and work-hours). So, what’s the best way to determine and select accurate AI translation?
In this post, we would like to briefly introduce four metrics that can be used when evaluating AI translation. All of these indicators are numerical values that indicate how close (or far) the AI translation output is to the human translation. This human translation is referred to as the "reference translation" or the "correct translation."
Indicator 1: BLEU
There are many metrics for evaluating AI translation, but the BLEU (BiLingual Evaluation Understudy) score is currently the most widely used.
The BLEU score is indicated by a numerical value between 0 and 1*, and the closer the translation is to the reference translation, the higher the numerical value. In other words, it can be said that the higher the numerical value, the closer the AI translation is to a human translation. As a general rule of thumb, a BLEU score of 0.4 or higher is considered high quality, and anything above 0.6 is considered higher quality than a human translation.
*Note: In some cases, the BLEU score is expressed as a percentage (%) multiplied by 100 instead of a number between 0 and 1.
It is evaluated based on a corpus, and long translations (with many words or characters) tend to be highly evaluated. In addition, since only the character information between translated sentences is evaluated, it is not possible to correctly evaluate broad-based order of words. (That means even if the word order is incorrect globally, it cannot be negatively evaluated).
Indicator 2: NIST
Like the BLEU score, the NIST score is also an index that indicates closeness between AI translation output and the reference translation.
The value is indicated by a positive real number (from 0 and above), and the closer to the reference translation, the higher the value. It seems as though this is often expressed by normalizing it to a range between 0 to 1 or 0 to 100. In these cases, the result will be 1 or 100 if the AI translation matches perfectly with the reference translation.
Different from the BLEU score is that weighting by the frequency of occurrence in the translation is taken into account. Therefore, low-frequency words such as content words tend to be rated higher than high-frequency words such as function words.
By the way, NIST is an abbreviation for America’s National Institute of Standards and Technology. This name is used because it is an evaluation method developed by NIST.
Indicator 3: RIBES
RIBES (Rank-based Intuitive Bilingual Evaluation Score) is an evaluation index with a different approach than the BLEU and NIST scores. It was developed at the NTT Communication Science Laboratories in Japan.
Since it is a numerical value based on the correlation of the order of words that appear in common in the translated texts to be compared, it is possible to accurately evaluate the word order in a wide range. It is said that this has a high correlation with evaluation by human translation review when evaluating translations between languages with large differences in word order, such as English and Japanese or Chinese and Japanese.
RIBES is indicated by a number between 0 and 1. The closer to the reference translation, the higher the number.
Indicator 4: WER
WER (Word Error Rate) is another approach to evaluation.
It works by comparing the AI translation output and reference translation — calculating word order and word edit distance and evaluating reciprocal consistency. Unlike the above three indicators, the smaller the value, the more accurate the AI translation.
All of these indices are statistical values, so the more bilingual corpora used for evaluation, the more meaningful the evaluation values. In other words, evaluating with a parallel corpus of 1,000 items yields a value closer to the actual accuracy of the machine translation than evaluating with a parallel corpus of 100 items.
Points to note when using evaluation metrics
Evaluation indexes, including the four indexes introduced in this post, are tools for evaluating different AI translations (i.e., AI translation engines) and comparing their values. In other words, it is important to note that you should use the values for each AI translation for relative comparison rather than seeing them as the absolute values for each index.
Customizing the AI translation engine
A recent trend has been the offering of services and products that customize AI translation engines to output better translations by specializing in fields and areas. There was a case where the BLEU score could be improved to 0.8 by limiting the field. In the future, it is expected that custom machine translation, which outputs highly accurate translations in limited fields, will become mainstream.
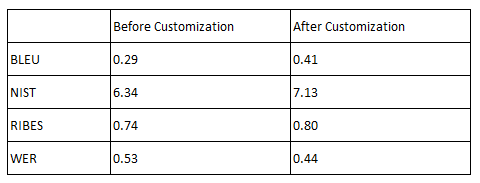
Let’s share what sort of numbers can actually be seen for example. Below are the evaluation values before and after customizing a certain AI translation engine. The data clearly shows that the accuracy has improved through customization and that the values differ depending on the indicator.
Kawamura's AI translation services
At Kawamura International, we can help you in situations where you’re not sure which AI translation engine best suits your company and your business. We offer a variety of options that can be flexibly customized to meet your security requirements, purpose, field, and the requirements of the expected user base.
Feel free to reach out to us if you have any questions on AI translation engines or machine translation in general.

